
Regression Discontinuity Lee 2001
Santa Cruz County Taxable Sales And Ppp Data
Cloud data training wheels with r.nb
Connecting python to aws rds db in the cloud
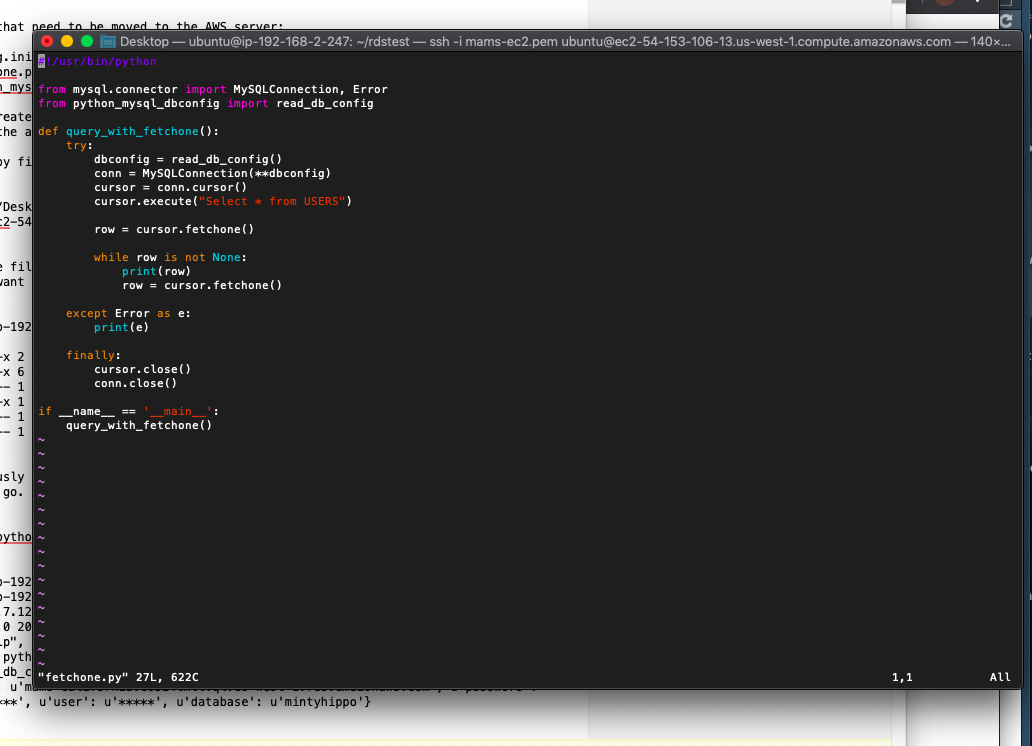
Cloud computing with python, mysql in aws
Another post I’m putting up mostly so I have something to refer to in a week when I forget how I did this.
Aws mysql db in a custom vpc
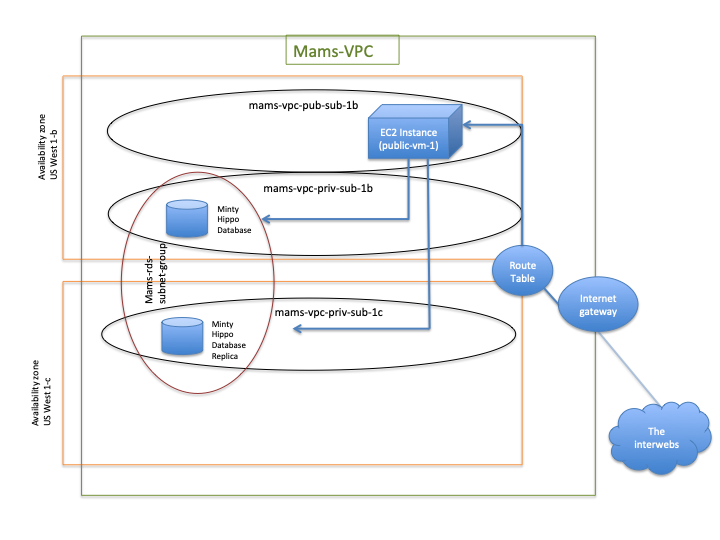
Connect to amazon rds db with mysql workbench
I’ve been wanting to beef-up my AWS skills for a long time. The main thing that’s slowed me down is that we cannot store government data on/in Amazon’s AWS ecosystem. This isn’t really a hard roadblock, it’s just that a lot of my blog content is generated from little programming or data hurdles I encounter at work.
Python virtual environments
Ml pipelines in r using caret
Fuzzy joins
Been a long time….if that intro didn’t immediately make you think of Christopher Walken than I’m begging you to watch this:
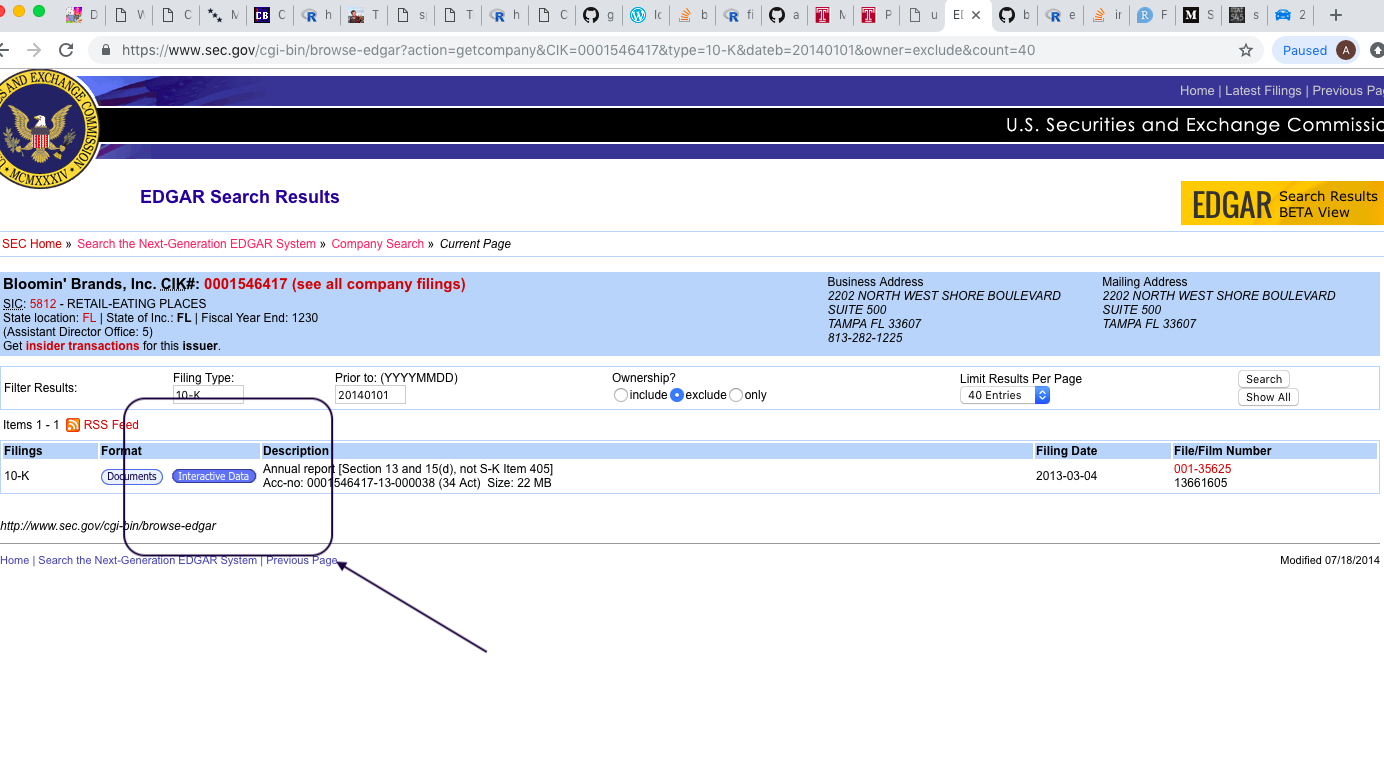
Accessing financial data from the sec part 2

Accessing financial data from the sec part 1
Many analysts one dataset
So I recently came across this cool little paper/project/effort:
Bayesian ab testing
so I had some fun messing around with a new R package for doing AB Testing in a Bayesian framework. Here’s my report:
Sqlite and rsqlite
Don't listen to arthur laffer, california's gonna be fine
Social vulnerability indicators with r
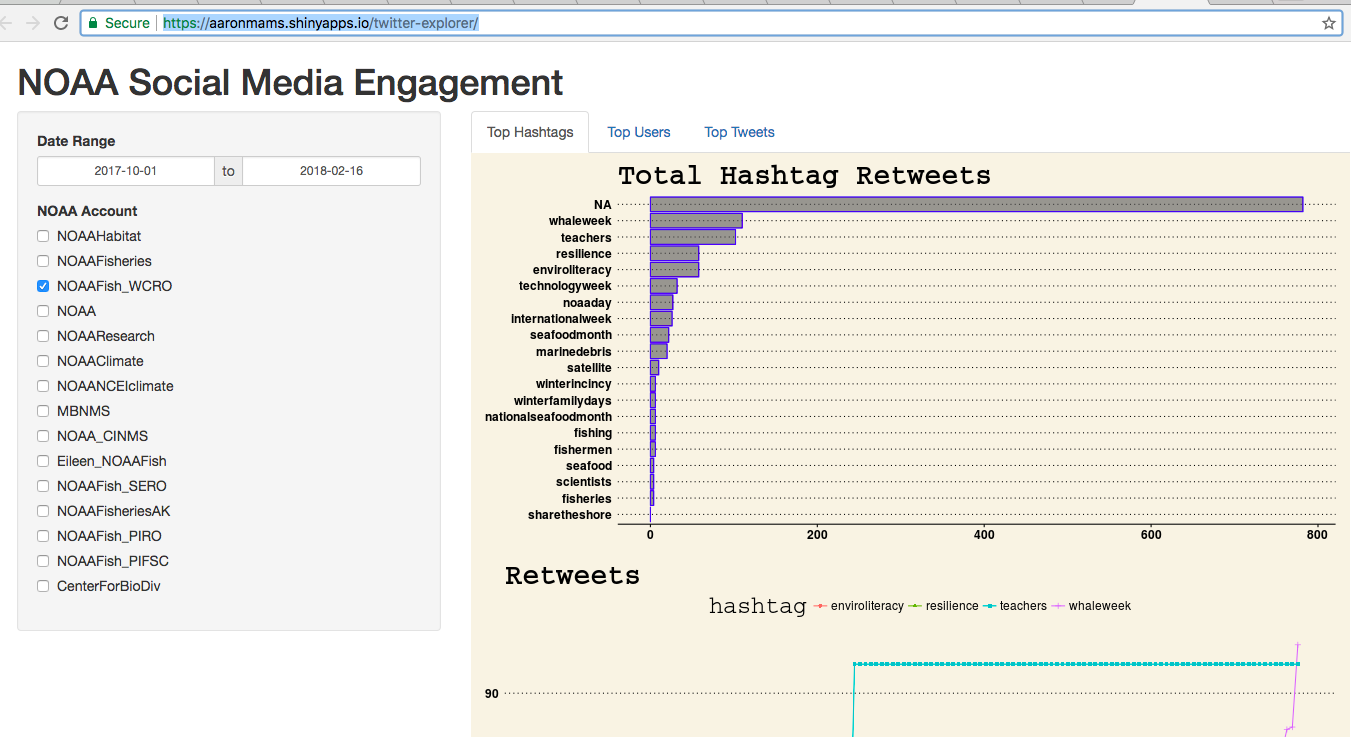
Twitter mining update #2
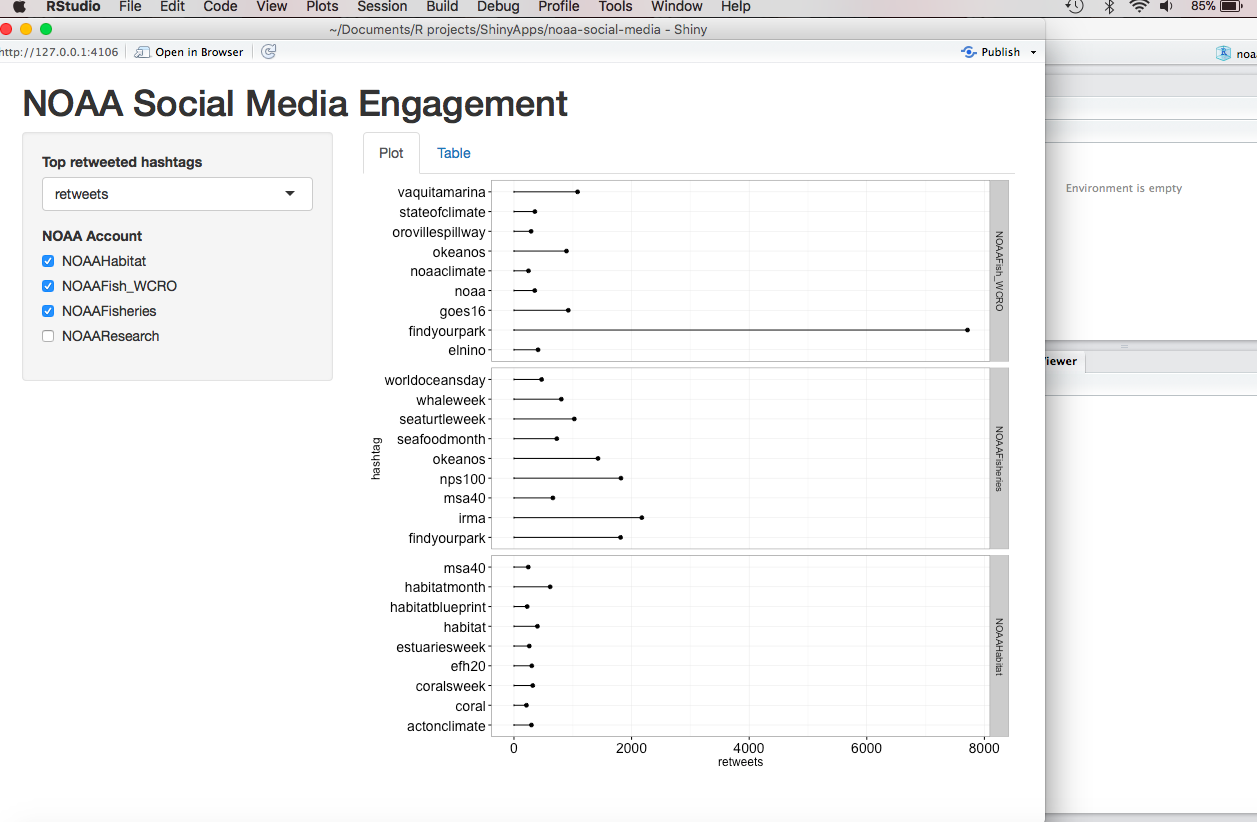
Twitter mining in r update
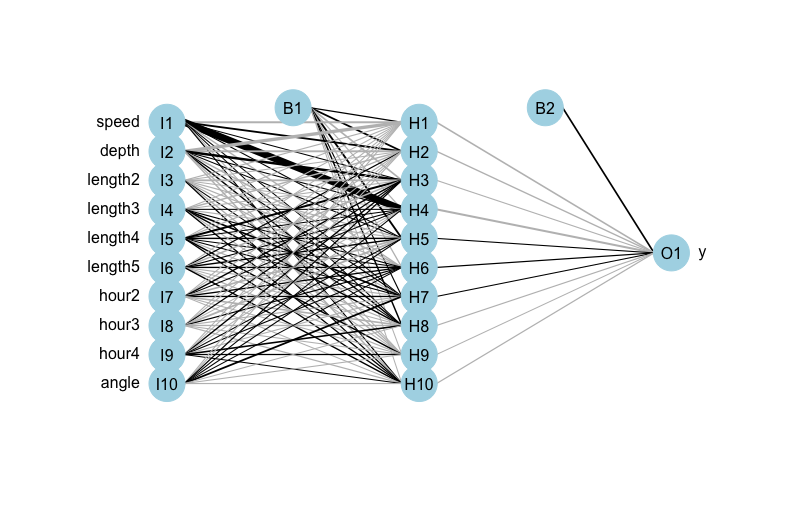
Machine learning pipelines 4 a simple pipeline
Yes, I’m still talking about pipelines…but in my defense I think we are starting to get to the really cool stuff.
More fun with data transformations
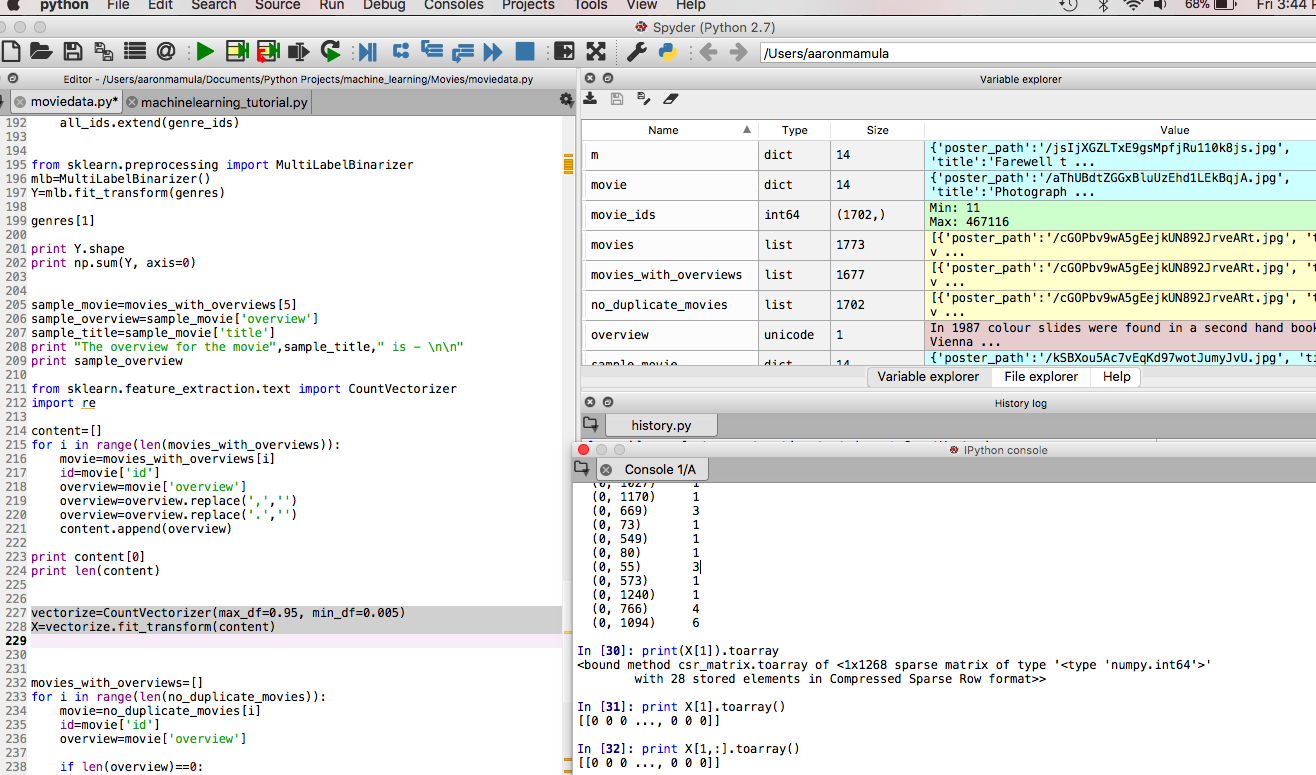
Machine learning pipelines 3 data streams
Ok, so we’ve been talking about pipelines here on the blog formerly known as The Samuelson Condition.
Data pipelines 2 data transformations
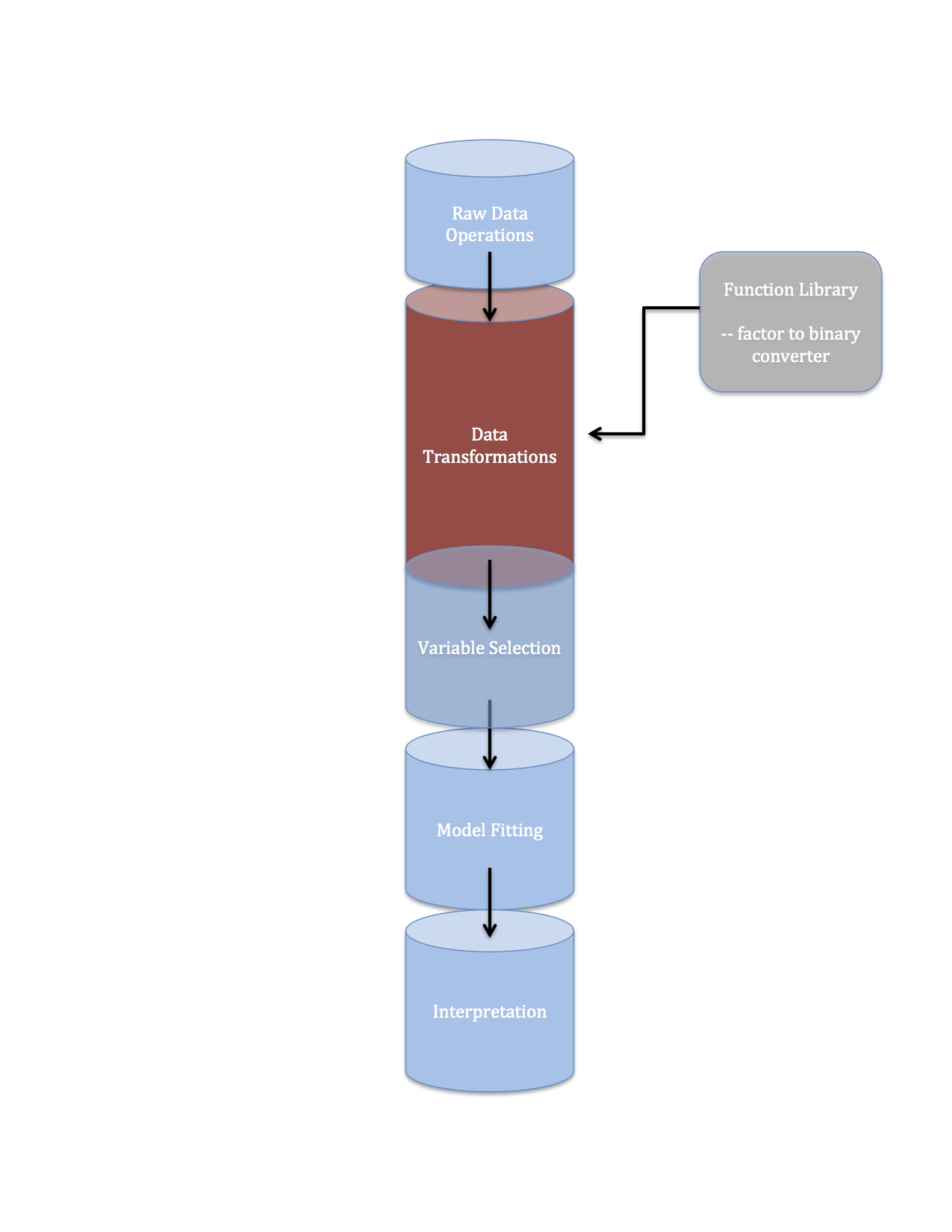
Machine learning pipelines part 1
To follow along with this post hop over to GitHub and clone my abalone-age repo.
Research notes visually identifying intervention effects
It will come as no surprise to people here that I think the concept of determining the impact of some event by looking at whether a line went up or down around the time of that event is farcical. I also realize that talking about the ‘correlation isn’t causation’ cliche to a bunch of statistically literate people is totally unnecessary. Yet, I feel compelled to write about this phenomenon because it’s so pervasive in my life:
A quick and dirty machine learning post with python and scikit Learn
I found this post on the interwebs and thought it was pretty cool. I mean, I’m not enamored with the whole, “don’t worry about understanding what it’s doing, just run the code and get a feel for how to do it” vibe…as a practicing empiricist I’m pretty well aware of the fact that anyone can run the same R/Python/whatever code that I use to run a Neural Network, Support Vector Machine, Classification-and-Regression Tree, insert hip new ensemble method here. The thing that makes me worth anything at all - if I am indeed worth anything - isn’t that I know how to tell R to train a Neural Network, it’s that I know what the code is doing when I give it that command. I have a decent (a little better than most, a lot worse than a few) grasp of the technical detail and nuance (read: the math) of the popular machine learning and applied statistical algorithms used to do prediction.
Machine learning and econometrics 1
Full disclosure: I’m not 100% confident that my assessment of Linear Discriminant Analysis relative to Logistic Regression is totally accurate. I’ve been thinking pretty hard about this for the past couple days so I’m reasonably confident that I’ve not said anything rediculous here…but if strongly disagree with characterization of LDA estimated coefficients relative to Logit coefficient estimates I’d love for you to drop some knowledge on me.
Three plots for wednesday
This is a little bit of rehash of an earlier post on President Cheeto Jesus’ economic agenda. The core message is basically the same, but the supporting evidence has been vastly simplified.
R shiny starter
I built my first R Shiny app. It’s laughably simple but, in this case, I think the simplicity will make for a good first blog post on R Shiny.
Affordable housing in santa cruz part 2 more thoughts on accessory dwelling units
In my last post I tried to set the stage for a discussion (one I’m pretty much just having with myself at the moment) on regional housing policy in Santa Cruz County. For whatever it’s worth, I also blogged about this a while back on The Samuelson Condition Blog. Today’s discussion on Accessory Dwelling Units will be decidedly more nuanced than what I wrote a year ago and, as any good Bayesian would when confronted with additional data points, my opposition to subsidized ADUs has softened somewhat.
Affordable housing in santa cruz part 1 what is a housing crisis
“A problem well posed is half solved.” – John Dewey.
Mining facebook with python proof of concept
This is going to be a pretty remedial post about using Facebook’s Graph API with Python. At this point I’ve only figured out how to do some pretty basic shit….enough to share but probably not enough to be really cool. I’m planning on posting a follow-up this week where I’ll focus on shoving the dictionary and list output you’ll see here into pandas dataframes.
Connect python to oracle db with pyodbc
I’m only the 3 billion-th blogger to write about this but for some reason, even with the interwebs saturated with python-Oracle connection examples, this still took me pretty much the whole day to figure out.
A python wrapper for pulling census bureau data
Super short post here because the day is pretty much over…but I just discovered a Python module for grabbing Census Data and I had to share.
Automating census data pulls with r
I had a pretty cool little quantitative micro-targeting of policy issues model I wanted to show you guys today. But I had to get this Census Bureau API-R relationship smoothed out for a work thing and I’m kinda thinking it will have more universal appeal. So I’m posting it first.
Working with shapefiles in r suck it esri!
I have been looking at other peoples’ awesome R-powered geospatial analysis for what feels like years and, until now, every time I’ve sat down to try and do some spatial analytics in R I’ve been stymied by wierd package load errors. I’ve been poking around this problem rather casually for several months and last night I think I finally made some tangible progress. I’m pretty stoked about this so I hope you will be too.
Can a robot learn economics
I spent a non-trivial amount of time this week trying to pick apart the code in R’s rgp package and Matlab’s GP tips to see if I could modify it to do coupled dynamical systems…I have no notable progress to report on this front.
Initial thoughts on genetic programming
I’ve been casually reading papers on Genetic Programming and Symbolic Regression for a little over a week now so I figured it was high time I stopped thinking about GP and started trying to DO a GP.
Sentiment analysis 4 naive bayes
I know I said last week’s post would be my final words on Twitter Mining/Sentiment Analysis/etc. for a while. I guess I lied. I didn’t feel great about the black box-y application of text classification…so I decided to add a little ‘under the hood’ post on Naive Bayes for text classification/sentiment analysis.
Sentiment Analysis with Python 3: just another example
After re-reading my last two posts on this topic, I felt like they were a little unfocused. I’m going to take one more shot at putting simple realistic example out there.
Sentiment analysis with python part 2
My first post on this topic was pretty rushed.
Sentiment analysis 1 twitter scraping with python
I didn’t have a ton of time today so this will be, I’m sure, mercifully short. Wanted to revisit something I tried to do a while back in R: scraping data from Twitter. R made the pretty easy with the twitteR package. This afternoon I tried to essentially repeat this post using Python.
Background
Researcher degrees of freedom, gartley patterns, and porn
Andrew Gelman writes a lot about p-hacking and ‘researcher degrees of freedom.’ I like his writing, his academic work, and his blog. You should check it out. He’s a great statistician, a great political scientist, and a true scholar.
Broken Windows, Carrots, Sticks, and Roe v Wade
The empirical section of this post is still a work-in-progress but the data and R scripts are available in my crime repository on GitHub.
Model-free quantification of time-series predictability
I read an interesting paper recently. I wrote a half-ass review of it here. Below I provide some notes and interesting nuggets I took from my reading of “Model-free quantification of time-series predictability” by Garland, Jame, and Bradley, published in Physical Review v. 90:
A Fun State Space Simulation Exercise
In this earlier post I tried to provide some helpful nuggets regarding the use of R’s KFAS package for modeling monthly seasonal data using a state space framework. I was going to add a little simulation experiment I cooked up just to further my understanding of how KFAS and state space models behave…but that post got a little long so I decided to include the simulation as a separate, companion post.
State Space Models with Seasonal Data
A little while back I wrote a few posts on time-series methods for seasonal data.
While I mentioned state space models as an option for modeling seasonal data, I didn’t really provide much meat there. In this post I’m going to give a few examples applying state space models (using the ‘KFAS’ package in R) to seasonal data.
Average Treatment Effect Examples
Here, I’ve added a bit more substance to an earlier post on quasi-treatement-control methods for social science research. More specifically, I’ve added some content on Propensity Score Matching to the discussion. Enjoy.
Blogging on GitHub Pages with Jekyll
For my first post on the new blog I’m going to provide yet another online look-up for how to get started hosting a Jekyll blog on GitHub Pages.