
Sentiment analysis 1 twitter scraping with python
I didn’t have a ton of time today so this will be, I’m sure, mercifully short. Wanted to revisit something I tried to do a while back in R: scraping data from Twitter. R made the pretty easy with the twitteR package. This afternoon I tried to essentially repeat this post using Python.
Background
I’ve been watching this guy’s tutorials on data analysis with Python and Pandas. He mentioned that he got really sold on Python because of its Natural Language Processing Toolkit….I guess he’s pretty into sentiment analysis. I did a little starter post a while back on using R to grab data from twitter but I never did any analysis on it. I now think I might be far enough along in my Pythoning to give it shot.
Quick Outline
Let’s imagine we want to do some sentiment analysis…how do people feel about my employer, NOAA Fisheries? To take a first cut at this we can:
- search Twitter for tweets mentioning @NOAAFisheries
- analyze these for positive v. negative or favorable v. unfavorable sentiment.
Some shit piled up today and I didn’t get around to doing the actual analysis part. So this post will be focused on just part 1: automating a search for tweets mentioning @NOAAFisheries. I’ll update this when I get a change to run the actual analysis.
Some References
There are a few different parts to this deal so I’ve taken the liberty of compiling some resources on each part:
- mining twitter data using Python:
- https://marcobonzanini.com/2015/03/02/mining-twitter-data-with-python-part-1/
- http://social-metrics.org/twitter-user-data/
- http://ataspinar.com/2015/11/09/collecting-data-from-twitter/
- http://www.craigaddyman.com/mining-all-tweets-with-python/
- setting up the content analysis
- http://www.laurentluce.com/posts/twitter-sentiment-analysis-using-python-and-nltk/
Step-by-Step
Step 1
I’ve been working with the ‘tweepy’ module for Python. So first I did a pip install of tweepy as recommended here…not a conda install. not really sure why.
Step 2
I’m skipping the part where you register an app in order to get access to the Twitter API and get:
- consumer_key
- consumer_secret
- access_token
- access_secret
because I covered that in my original R-focused post.
I searched Twitter for tweets involving @NOAAFisheries but filtered out retweets like so:
import tweepy
from tweepy import OAuthHandler
consumer_key = ''
consumer_secret = ''
access_token = ''
access_secret = ''
auth = OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_secret)
api = tweepy.API(auth)
import csv
# Open/Create a file to append data
csvFile = open('result.csv', 'a')
#Use csv Writer
csvWriter = csv.writer(csvFile)
for tweet in tweepy.Cursor(api.search, q="@NOAAFisheries-filter:retweets").items():
#Write a row to the csv file/ I use encode utf-8
csvWriter.writerow([tweet.created_at, tweet.text.encode('utf-8')])
print tweet.created_at, tweet.text
csvFile.close()
Note that I elected to save the results of the search to a .csv file. I’m sure it’s reasonably easy to just write the tweets into a local list or something but I was looking for the least cost path…and for me that was writing to a .csv
Not that they won’t be super informative but here are a few visuals of the data we created with out Twitter search:
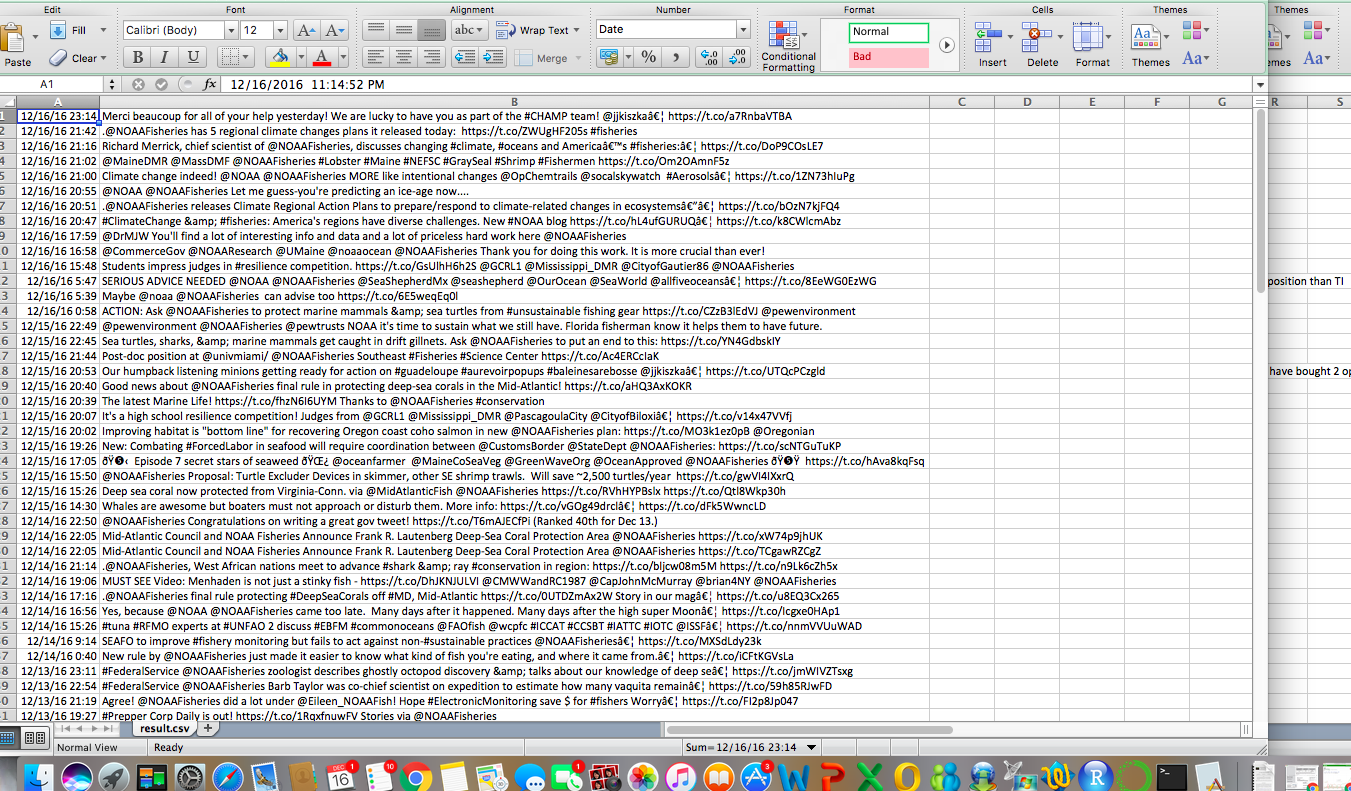
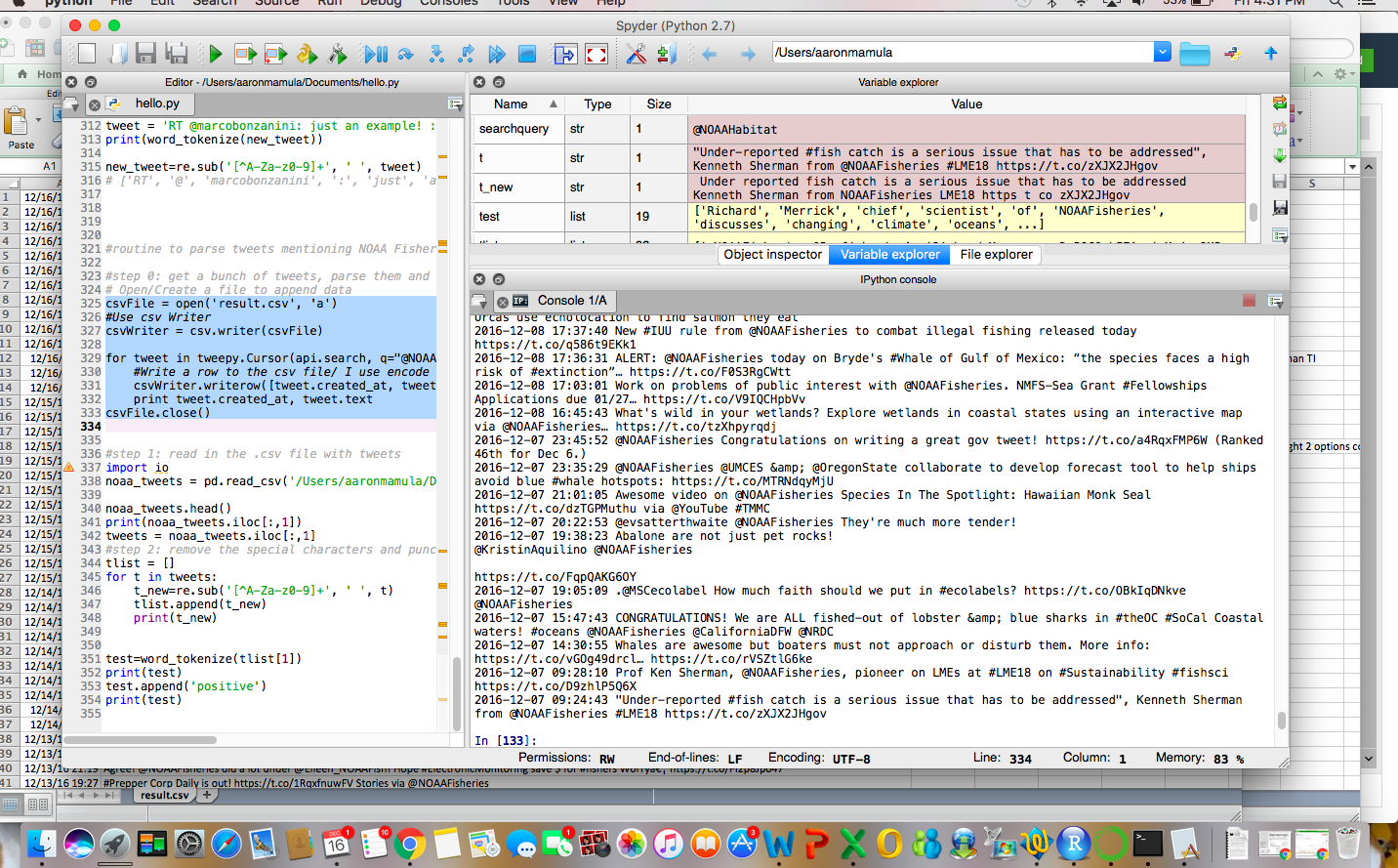
Step 2
OK, now we have a reasonably robust set of tweets. We’re going to read them in from our .csv and parse them. There are lots of ways we could parse out the texts and, for sentiment analysis we probably should be careful about how we treat things like hashtags, emojis and such…but I don’t feel like being that careful right now. As a first pass I think it’s good enough to just get the words…our classifier is ultimately just going to use words in the training set to learn what a positive v. negative combination is.
import re
import io
noaa_tweets = pd.read_csv('/Users/aaronmamula/Documents/blog posts/result.csv')
noaa_tweets.head()
print(noaa_tweets.iloc[:,1])
tweets = noaa_tweets.iloc[:,1]
#step 2: remove the special characters and punctuation
tlist = []
for t in tweets:
t_new=re.sub('[^A-Za-z0-9]+', ' ', t)
tlist.append(t_new)
print(t_new)
from nltk.tokenize import word_tokenize
import nltk
nltk.download('punkt')
test=word_tokenize(tlist[1])
print(test)
['Richard', 'Merrick', 'chief', 'scientist', 'of', 'NOAAFisheries', 'discusses', 'changing', 'climate', 'oceans', 'and', 'America', 's', 'fisheries', 'https', 't', 'co', 'DoP9COsLE7']
Next Steps:
So from here we have a few things left to do in order to be able to use some Machine Learning algorithms to classify tweets for us:
Train a test set
We have a decent set of tweets that we scrapped from Twitter but now we need to classify them. I currently have the tweets stored in a list and what I plan to do next is append that list so that each of those tokenized tweets is associated with a ‘positive’ or ‘negative’ sentiment. Also, since a lot of the tweets involving NOAA Fisheries are news items I think I’ll add a third classifier: ‘neutral’. I imagine the new list I will want to create will look something like this:
[('Richard', 'Merrick', 'chief', 'scientist', 'of', 'NOAAFisheries', 'discusses', 'changing', 'climate', 'oceans', 'and', 'America', 's', 'fisheries', 'https', 't', 'co', 'DoP9COsLE7'),'neutral',
('NOAA','lax', 'hatchery','regs','killing','native','fish','must','act','now'),'negative']
Use the training set to classify new tweets
This is where the fun stuff happens. Here we can leverage any number of supervised machine learning approaches (Naive Bayes, Support Vector Machines, etc) to do the actual classification.
Final Notes
Both the Python and R solutions I’ve worked with are limited by Twitter’s API in the sense that you can only get about a weeks worth of tweets matching any set of search terms. For something like sentiment dynamics this is not terribly limiting…basically what you would be using the Twitter stream for is:
- You have an existing ‘sentiment’ score: favorable/unfavorable etc
- It was updated yesterday
- Today, your app runs, collects tweets mentioning @NOAAFisheries and classifies them.
- The sentiment score is update and the change is displayed