
Twitter mining in r update
A while back I wrote a couple posts about mining Twitter data for sentiment analysis on environmental/conservation causes. I have had occassion to revisit that work and found a pretty neat improvement over the TwittR package I was using before.
Here is my original post for reference
and
Here and here are some extensions to the original R-based post that explore Python solutions.
Today’s short post will illustrate the use of the rtweet package for harvesting Twitter Data.
Motivation
My elevator pitch for why I think this type of stuff could be cool: I work for NOAA Fisheries. We have a bunch of research and policy interests relating to environmental stewardship:
- we are the primary agency in charge of regulating a large swath of commercial fisheries
- we have a regulatory responsibility to protect endangered species such as sea turtles, salmon and steelhead, and a bunch of marine mammals like whales and sea lions.
- all the stuff we do is getting more complicated because of climate change
- etc, etc.
so I think it would be cool to know what types of things that we do really resonate with the public. The current way of assessing attitudes and intrinsic values of environmental conservation is to survey people. Surveys costs millions of dollars and take years to do correctly. Social media engagement is far from perfect in terms of being a tool or metric for assessing public sentiment around environmental issues….but it’s cheap, data driven, and fun.
Overview
- Use rtweets to get Twitter activity for a handful of NOAA related accounts
- Extract the most retweeted hashtags from NOAA posts
- Plot most retweeted hashtags
Execution
The actual code I’m using is pretty compact but I’m going to walk through it in steps because there are some notably different behaviors between rtweet and TwittR.
Step 1: Collect all the tweets from the different NOAA accounts
As I stated above, NOAA has a lot of interests:
- we have branches that are very interested in cod populations in New England
- we have branches that are really interested in agricultural water use in California (to the extent that this use makes it harder for salmon to survive)
- we have branches that launch satellites
- we have branches that are very interested in artisnal lobster fishing among marginalized populations in Southern Florida.
Because of the varied branches and varied interest there are a lot of different NOAA-related Twitter Accounts. For the time being I’m contraining my analysis to the following branches/offices/accounts
- The NOAA Office of Habitat Conservation (@NOAAHabitat)
- The NOAA Fisheries West Coast Regional Office (@NOAAFish_WCRO)
- NOAA Fisheries (@NOAAFisheries)
- The NOAA Research Account (@NOAAResearch)
I’ll probably widen this list considerably but it’s a decent place to start.
require(twitteR)
library(data.table)
library(dplyr)
library(ggplot2)
library(rtweet)
library(RODBC)
#----------------------------------------------------------------------------
#Now we do a data pull
users <- c('@NOAAHabitat','@NOAAFisheries','@NOAAFish_WCRO','@NOAA','@NOAAResearch')
# get tweets from each of our accounts
tl <- lapply(users,function(x){
rt <- get_timeline(
x, n = 1000, include_rts = FALSE
)
tl <- data.frame(rbindlist(tl))
tl <- tl %>% select(created_at,user_id,screen_name,text,
is_quote,is_retweet,favorite_count,
retweet_count,hashtags,mentions_screen_name) %>%
mutate(update_time=Sys.time())
#fix hashtags
hash <- unlist(lapply(tl$hashtags,function(x){collapse(c(unlist(x)),sep=";")}))
tl <- tl %>% mutate(hash1=hash) %>%
select(-hashtags) %>%
mutate(hashtags=hash1) %>%
select(-hash1)
#fix @ mentions
mentions <- unlist(lapply(tl$mentions_screen_name,function(x){collapse(c(unlist(x)),sep=";")}))
tl <- tl %>% mutate(mentions1=mentions) %>%
select(-mentions_screen_name) %>%
mutate(mentions=mentions1) %>%
select(-mentions1)
In the TwittR package one could do:
R
search_twitter('from:@NOAAHabitat')
and this would return the most recent tweets from the account: @NOAAHabitat. I couldn’t find a similar method with the rtweet package…but I didn’t look too hard because the method:
get_timeline('@NOAAHabitat,n=1000)
will pull all of the most recent 1,000 tweets from @NOAAHabitat
What I find exceptionally cool about the rtweet package is that when you use the get_timeline() function it returns the tweets in a dplyr data frame with a ton - A TON I tell you! - of meta-data on the tweet and user.
In the example above, I’ve chosen to save:
- the creation date of each tweet
- screen name of the user
- user id
- text of the tweet
- number of retweets
- number of favorites
- hashtags used in the tweet
- @ mentions for the tweet.
- a flag for whether the tweet is a retweet or not
- an ‘update time’ which is the date-time that I made the data pull
One important thing to note here (which will also be important in step 2): the columns for hashtags and @mentions in the data frame resulting from the get_timeline() call are lists. Before we can save this data frame as an R data frame we need to coerce that list to a more acceptable data type. There are probably other solutions but I have chosen to convert the list associated with each row to a single character vector where the individual hashtags from the original list are separated by “;”. This will make it pretty easy to parse out the individual hashtags later, should I want to do that.
Note, I do the same thing for @mentions.
Step 2: get tweets from other users that mention the NOAA accounts
The get_timeline() method gives us tweets from the accounts we are interested in. If we also want tweets that mention those account we can use the search_tweets() method.
#-----------------------------------------------------------------------------------
#get tweets mentioning user, save them as a data frame, then bind the data frames
df <- lapply(users,function(x){
rt <- search_tweets(
x, n = 1000, include_rts = FALSE
)
df <- rt %>% select(created_at,user_id,screen_name,text,
is_quote,is_retweet,favorite_count,
retweet_count,hashtags,mentions_screen_name) %>%
mutate(update_time=Sys.time())
return(df)
})
df <- data.frame(rbindlist(df))
#fix hashtag list
hash <- unlist(lapply(df$hashtags,function(x){collapse(c(unlist(x)),sep=";")}))
df <- df %>% mutate(hash1=hash) %>%
select(-hashtags) %>%
mutate(hashtags=hash1) %>%
select(-hash1)
#fix the @ mention list
mentions <- unlist(lapply(df$mentions_screen_name,function(x){collapse(c(unlist(x)),sep=";")}))
df <- df %>% mutate(mentions1=mentions) %>%
select(-mentions_screen_name) %>%
mutate(mentions=mentions1) %>%
select(-mentions1)
#--------------------------------------------------------------------------
Step 3: get meta-data on the users
New tweets come in frequently so we will probably want to refresh the data on individual tweets at pretty regular intervals. Information on users however (user description, user location, follower) probably changes less frequently. At the moment I’m choosing to update this info less frequently and save it in a separate table in a relational database so I don’t end up repeating a lot of info as I would if I joined this user info with the tweet info in a flat file.
user.info <- lapply(users,function(x){
user.info <- search_users(x) %>%
select(user_id,name,screen_name,location,description,followers_count,
friends_count)
return(user.info)
})
user.info <- data.frame(rbindlist(user.info))
#---------------------------------------------------------------------------------
Extensions
Extension 1: Database push-pull
I’ve set up a relational database to store these data. The code above will get updated info on users and tweets. My next step is integrate this code in a process that will (i) open the old database tables, (ii) update the tables with the new stuff, (iii) check to see if any of the new data are duplicates of the old stuff, (iv) save the updated table.
Extension 2: Error handling
I need to add some error handling into the data pull code. For what I’m pulling here I haven’t had to deal with timeout issues but if I add other NOAA account or accounts of other conservation groups I might. R has some error handling processes that I can probably wrap into loops so that if the process times-out during one of the requests, the loop can just restart.
tryCatch seems like the way to go here.
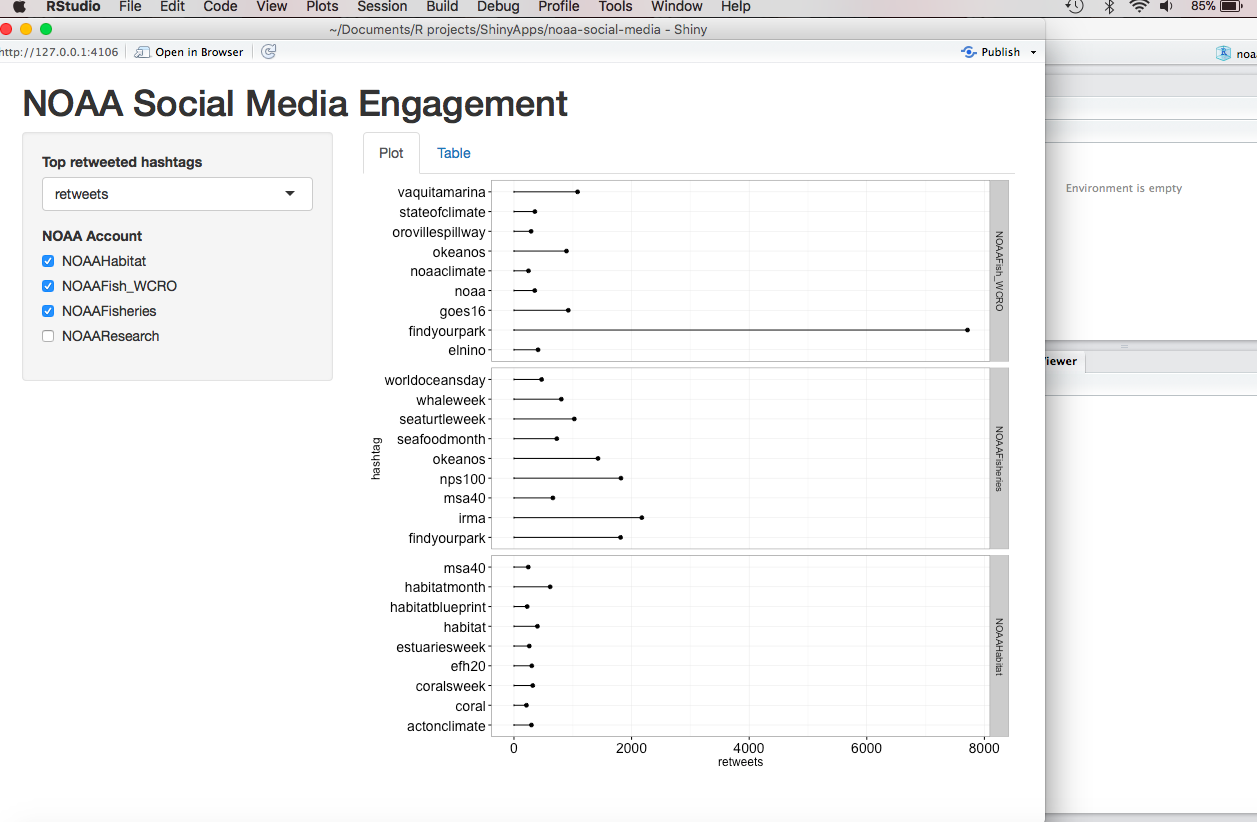
Extension 3: Analyzing the data
As a first step here I’ve aggregated retweets per hashtag for each of my NOAA twitter accounts. I’ve built a super simple R Shiny app to display this data. The image at the top of the page is a screen shot of this Shiny App. I’ll try to get the app up on the interwebs this weekend after I sexy it up a little. Next, I want to add some more metrics to this list:
- most retweeted hashtags from tweets that @mention NOAA
- follower count over time
- hashtag engagement over time (by week or month).