
Machine learning pipelines 3 data streams
Ok, so we’ve been talking about pipelines here on the blog formerly known as The Samuelson Condition.
Here I tried to provide a little roadmap for what I argued was kind of a data pipeline written in R.
In this follow-up I tried to kind of zoom in on the ‘Data Transformations’ stage in the pipeline and discuss how to use the R Package tidytext to prepare some word count data for entry into a machine learner.
This post will be another zoomed-in look at one of the important steps in a Machine Learning pipeline: establishing the data stream.
Looking Forward
So in this post I’m still talking sort of philosophically about what pipelines are and how differnt scripting tasks fit together to form a pipeline. I have one more post in mind where I want to break down one final aspect of a good pipeline. After that, I’m going to try and bring everything together under the Python sklearn.pipeline.Pipeline() function.
Problem Statement
The basic problem I’m going to deal with in this post is how to set up a connection to a data stream. Specifically, I’m going to connect to The Movie Database and run a Python Script to pull a bunch of data on movies.
I argued in my Part 1 post that pipelines are especially valuable for applications that make use of data streams. Applications where new data comes in at regular intervals and the analytics need to either be updated to reflect new inputs to the training data or new predictions need to be generated based on some new data.
For that reason, I’m presenting this web-scraping application that I really like. True, this particular application isn’t a great example of something that would be updated at regular intervals…but the basic mechanics generalize very well to cases where one would be uploading new data nightly/weekly/whatever and rerunning some analytics.
For an example of how this might generalize, recall the webscraping example I provided here using Twitter data. Since Twitter only let’s you scrap the most recent 7 days of data with their API, a text mining analysis using Twitter data might need to have its data refreshed at pretty regular intervals.
Resources
-
I’ve borrowed almost all of the code for this post from a really killer machine learning tutorial here.
-
It’s also worth going over to The Movie Database and checking out the intro on setting up an account and getting an API key
-
If you are more interested in practicing with a example of a data stream that should be regularly updated, please have a look at my post on scraping Twitter data with Python.
Overview
- Get an API key from The Movie Database
- Load the tmdbsimple Python library
- Use the API to pipe in a bunch of info about movies
- Do some basic data curation/warehousing
Execution
A testing scrip
Here is a ‘testing’ chunk…just something to play around with the API interface and see what options we have for pulling movie data.
#Import a bunch of libraries--------------
import tmdbsimple as tmdb
import json
import pickle
import time
import itertools
import numpy as np
import urllib2
import requests
#import wget
import os
import random
import matplotlib
import matplotlib.pyplot as plt
#%matplotlib inline
import seaborn as sns
#-------------------------------------------
#--------------------------------------------
api_key = '' #Enter your own API key here to run the code below.
tmdb.API_KEY = api_key #This sets the API key setting for the tmdb object
search = tmdb.Search() #this instantiates a tmdb "search" object which allows you to search for the movie
#set up a function for getting movie info
def get_movie_info_tmdb(movie):
response = search.movie(query=movie)
id=response['results'][0]['id']
movie = tmdb.Movies(id)
info=movie.info()
return info
info=get_movie_info_tmdb("The Matrix")
print "All the Movie information from TMDB gets stored in a dictionary with the following keys for easy access -"
info.keys()
All the Movie information from TMDB gets stored in a dictionary with the following keys for easy access -
Out[1]:
[u'poster_path',
u'production_countries',
u'revenue',
u'overview',
u'video',
u'id',
u'genres',
u'title',
u'tagline',
u'vote_count',
u'homepage',
u'belongs_to_collection',
u'original_language',
u'status',
u'spoken_languages',
u'imdb_id',
u'adult',
u'backdrop_path',
u'production_companies',
u'release_date',
u'popularity',
u'original_title',
u'budget',
u'vote_average',
u'runtime']
#---------------------------------------------------
#----------------------------------------------------
all_movies=tmdb.Movies()
top_movies=all_movies.popular()
# This is a dictionary, and to access results we use the key 'results' which returns info on 20 movies
len(top_movies['results'])
top20_movs=top_movies['results']
#now print one of the elements just to see what we're dealing with:
top20_movs[0]
Out[5]:
{u'adult': False,
u'backdrop_path': u'/tcheoA2nPATCm2vvXw2hVQoaEFD.jpg',
u'genre_ids': [18, 27, 53],
u'id': 346364,
u'original_language': u'en',
u'original_title': u'It',
u'overview': u'In a small town in Maine, seven children known as The Losers Club come face to face with life problems, bullies and a monster that takes the shape of a clown called Pennywise.',
u'popularity': 710.916995,
u'poster_path': u'/9E2y5Q7WlCVNEhP5GiVTjhEhx1o.jpg',
u'release_date': u'2017-09-05',
u'title': u'It',
u'video': False,
u'vote_average': 7.1,
u'vote_count': 5876}
#-------------------------------------------------------
Some things worth noting:
- The movie ‘It’ has the genre ids 18, 27, and 53
- The movie ‘It’ has the following overview, “In a small town in Maine, seven children known as The Losers Club come face to face with life problems, bullies and a monster that takes the shape of a clown called Pennywise.”
These are kind of cool pieces of info that I can probably do something with.
The real deal
Here’s the real action:
Suppose our question, as I alluded to here, is whether we can predict the genre of a movie from the words in the movie overview.
So what we want to do is piece together a training set of data that has a bunch of movie overviews and the genres that those movies are assigned to.
So here are the steps:
-
get a list of Genre IDs
-
pull a bunch of movies from each genre
-
Optional 3rd Step: save the data so we don’t have to stream for the API everytime we want to change the analysis
Step 1: Get a list of unique movie genres
#------------------------------------------------------------
# get the Top 1000 movies and pickle them just for fun
all_movies=tmdb.Movies()
top1000_movies=[]
print('Pulling movie list, Please wait...')
for i in range(1,51):
if i%15==0:
time.sleep(7)
movies_on_this_page=all_movies.popular(page=i)['results']
top1000_movies.extend(movies_on_this_page)
len(top1000_movies)
f3=open('movie_list.pckl','wb')
pickle.dump(top1000_movies,f3)
f3.close()
print('Done!')
#-------------------------------------------------------------
#-------------------------------------------------------------
f3=open('movie_list.pckl','rb')
top1000_movies=pickle.load(f3)
f3.close()
#--------------------------------------------------------------
#--------------------------------------------------------------
# Now extract a list of genres for the movies
def list2pairs(l):
# itertools.combinations(l,2) makes all pairs of length 2 from list l.
pairs = list(itertools.combinations(l, 2))
# then the one item pairs, as duplicate pairs aren't accounted for by itertools
for i in l:
pairs.append([i,i])
return pairs
# get all genre lists pairs from all movies
allPairs = []
for movie in top1000_movies:
allPairs.extend(list2pairs(movie['genre_ids']))
nr_ids = np.unique(allPairs)
#---------------------------------------------------------------
Step 2: Pull a bunch of movies from each genre
#---------------------------------------------------------------
# Now for each of those genres pull the first 100 movies
movies = []
baseyear = 2017
print('Starting pulling movies from TMDB. If you want to debug, uncomment the print command. This will take a while, please wait...')
done_ids=[]
for g_id in nr_ids:
baseyear -= 1
for page in xrange(1,6,1):
time.sleep(0.5)
url = 'https://api.themoviedb.org/3/discover/movie?api_key=' + api_key
url += '&language=en-US&sort_by=popularity.desc&year=' + str(baseyear)
url += '&with_genres=' + str(g_id) + '&page=' + str(page)
data = urllib2.urlopen(url).read()
dataDict = json.loads(data)
movies.extend(dataDict["results"])
done_ids.append(str(g_id))
print("Pulled movies for genres - "+','.join(done_ids))
Starting pulling movies from TMDB. If you want to debug, uncomment the print command. This will take a while, please wait...
Pulled movies for genres - 12,14,16,18,27,28,35,36,37,53,80,99,878,9648,10402,10749,10751,10752,10770
#---------------------------------------------------------------
So, at this point we have a giant list of movies with a bunch of info on each of those movies. Let’s see what that giant list looks like
movies[0]
Out[3]:
{u'adult': False,
u'backdrop_path': u'/6I2tPx6KIiBB4TWFiWwNUzrbxUn.jpg',
u'genre_ids': [12, 10751, 14],
u'id': 259316,
u'original_language': u'en',
u'original_title': u'Fantastic Beasts and Where to Find Them',
u'overview': u'In 1926, Newt Scamander arrives at the Magical Congress of the United States of America with a magically expanded briefcase, which houses a number of dangerous creatures and their habitats. When the creatures escape from the briefcase, it sends the American wizarding authorities after Newt, and threatens to strain even further the state of magical and non-magical relations.',
u'popularity': 120.727119,
u'poster_path': u'/gri0DDxsERr6B2sOR1fGLxLpSLx.jpg',
u'release_date': u'2016-11-16',
u'title': u'Fantastic Beasts and Where to Find Them',
u'video': False,
u'vote_average': 7.2,
u'vote_count': 6687}
So each element in the list is a movie with a bunch of feature of that movie.
len(movies)
Out[4]: 1773
And it appears that we’ve compiled a list of 1773 movies.
Optional Step 3: Save the results
For reproducability it’s nice to have code that can be used to re-load the raw data. However, for speed and testing you may not want to re-run a web scraping script literally everytime you want to repeat or change something about your analysis. So after the data have been scraped you may want to save them to a local file or a database.
In the picture below I tried to illustrate a skeletal version of a pipeline and how the scrap-save process enters in. Basically, what I’m trying to show here is that, generally, when I initiate some analysis the first question is usually: do I need to update the data?
If the data have been refreshed pretty recently, I may not want to go through the hassle of re-running a scraping routine or re-compiling a data set from a bunch of raw files. Maybe I can just pull from an existing database.
If the data need to be updated then I first need to establish the parameters for the data update. Maybe the data are updated at the source every day but I haven’t updated my database in about a week. Then I probably want to define some query parameters (“last 7 days” for example) and download the new data I want.
Finally, after I have my new data, I should push it to the existing database so my database stays reasonably up-to-date.
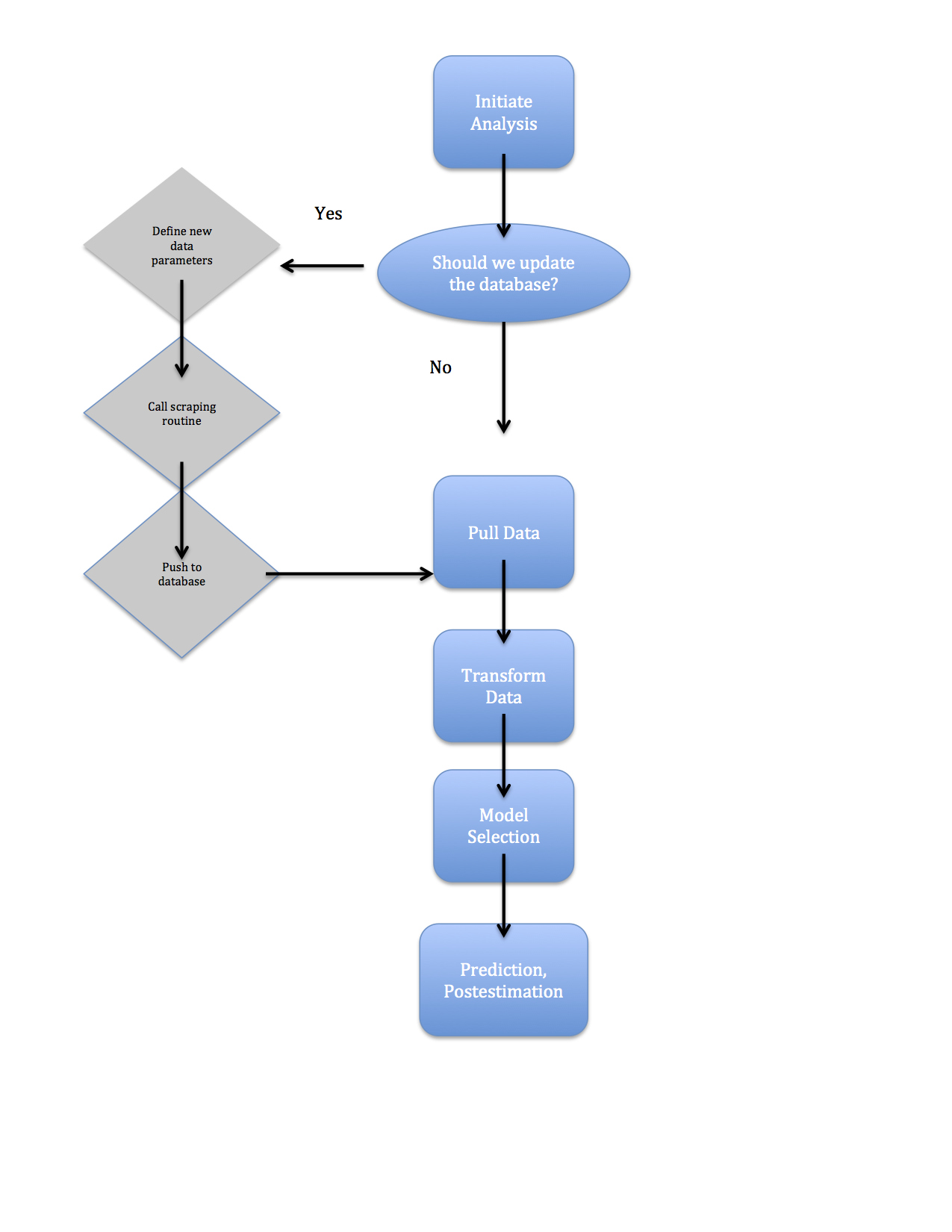
Here’s a quick example of a save-load-manipulate process using the Python dictionary on movie info that we created above:
# I don't have a database set up for these data yet so I'm just going to write them to a pickle file that
# I can read from later...rather than scraping the web all over again.
#============================================================
#pickle this movie list
f3=open('/Users/aaronmamula/Documents/Python Projects/machine_learning/Movies/movie_data.pckl','wb')
pickle.dump(movies, f3)
f3.close()
#============================================================
All I did there was save the “movies” dictionary that we created with the web-scraping routine to a local pickle file.
Now, I’m going to read that file back into memory and coerce it from a dictionary into a Pandas dataframe.
#============================================================
f3=open('/Users/aaronmamula/Documents/Python Projects/machine_learning/Movies/movie_data.pckl','rb')
movie_data=pickle.load(f3)
f3.close()
#============================================================
#as an added bonus coerce this movie data to a pandas data frame
movies_dataframe=pd.DataFrame(movies)
movies_dataframe.head()
Out[18]:
adult backdrop_path genre_ids id \
0 False /6I2tPx6KIiBB4TWFiWwNUzrbxUn.jpg [12, 10751, 14] 259316
1 False /n1y094tVDFATSzkTnFxoGZ1qNsG.jpg [28, 12, 35] 293660
2 False /9BVHn78oQcFCRd4M3u3NT7OrhTk.jpg [18, 14, 12] 283366
3 False /wVTYlkKPKrljJfugXN7UlLNjtuJ.jpg [28, 12, 80] 206647
4 False /tFI8VLMgSTTU38i8TIsklfqS9Nl.jpg [28, 12, 14, 878] 284052
original_language original_title \
0 en Fantastic Beasts and Where to Find Them
1 en Deadpool
2 en Miss Peregrine's Home for Peculiar Children
3 en Spectre
4 en Doctor Strange
overview popularity \
0 In 1926, Newt Scamander arrives at the Magical... 120.727119
1 Deadpool tells the origin story of former Spec... 82.799628
2 A teenager finds himself transported to an isl... 78.587697
3 A cryptic message from Bond’s past sends him o... 77.723960
4 After his career is destroyed, a brilliant but... 77.550242
poster_path release_date \
0 /gri0DDxsERr6B2sOR1fGLxLpSLx.jpg 2016-11-16
1 /inVq3FRqcYIRl2la8iZikYYxFNR.jpg 2016-02-09
2 /tzYkC0vqX8Dokuwynhz1lnWWgWT.jpg 2016-09-28
3 /hE24GYddaxB9MVZl1CaiI86M3kp.jpg 2015-10-26
4 /4PiiNGXj1KENTmCBHeN6Mskj2Fq.jpg 2016-10-25
title video vote_average \
0 Fantastic Beasts and Where to Find Them False 7.2
1 Deadpool False 7.4
2 Miss Peregrine's Home for Peculiar Children False 6.6
3 Spectre False 6.3
4 Doctor Strange False 7.2
vote_count
0 6687
1 13016
2 3921
3 5009
4 7006
Totally Unrelated Rant
I’ve been trying to teach myself Python off-and-on for about a year. I spend anywhere from 2 hrs/week to 2 hrs/month dicking around in Python. I use blog posts a lot. Really, A LOT.
I tried to do some formal courses but they really pissed me off. I signed up for a free Coursera course. I’m well aware that, with a free course, you pretty much get what you pay for but I figured since I was on square 1 anything was better than nothing. I was wrong. The course was like 3 20 minute modules that basically covered things like how to turn your computer on. After the 3 free modules they started hitting you up to sign up for a fee-based class.
I also tried the Udacity, “Programming Foundations with Python” and found this one to be disappointing as well. It didn’t seem to me to be as much about learning Python as learning how to code. Since I already code pretty well in R, Fortran, C, Matlab, etc., I guess I was just looking for something different.
I’m sure there are some baller-ass Python classes out there…but I haven’t found one yet. For the time being I think I’m just better off following along with blog posts, Stack Overflowing the fuck out of questions, and using the 3 Python books I checked out of library to learn.